
No artigo “Migrando de Monolito para Microsserviços” apresentamos as principais questões associadas à refatoração de uma aplicação para a arquitetura de microsserviços. Embora se possa simplesmente reescrever a aplicação, estratégia conhecida como “big bang rewrite”, raramente essa aproximação é utilizada. O mais natural é realizar uma migração gradativa da funcionalidade da aplicação monolítica para a nova arquitetura. Esse processo pode ser demorado, dependendo do tamanho da aplicação.
A migração gradativa implica na convivência, durante o processo de migração, entre a aplicação monolítica e a nova aplicação baseada em microsserviços. Esse processo de migração gradativa envolve algumas ações importantes;
- Separar a camada de apresentação da camada de negócios e dados;
- Implementar novas funcionalidades da aplicação já na nova arquitetura;
- Extração de funcionalidades de negócio da aplicação, construindo-as em microsserviços.
Neste artigo vamos nos aprofundar em cada uma dessas ações.
Separar a camada de apresentação das camadas de negócio e dados
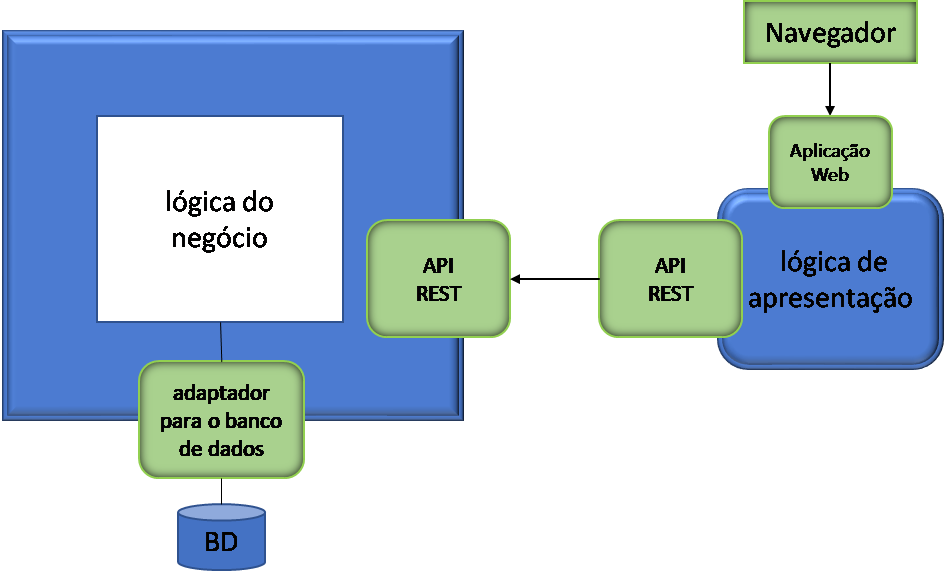
O primeiro passo importante para viabilizar a migração de um monolito para a arquitetura de microsserviços é garantir a separação entre as camadas de apresentação e de negócios e dados. Essa separação deve ser feita de maneira a garantir que a camada de apresentação se comunique com a aplicação. E isso deverá ocorrer exclusivamente através de uma API, que encapsulará a funcionalidade de negócios e dados. A construção dessa API viabilizará a separação futura entre funcionalidades atendidas pelo monolito e as atendidas pela nova arquitetura de microsserviços.
Como resultado desse processo teremos:
- Uma aplicação que implementa a lógica de apresentação e que acessa a camada de negócios e dados através de uma API;
- Uma aplicação que implementa a lógica de negócios e dados;
- Uma API que encapsula a lógica do negócio que pode utilizar, por exemplo, o modelo REST ou GraphQL.
Essa API futuramente também será usada pelos novos microsserviços para acessar funcionalidades, e eventualmente dados, da aplicação monolítica, enquanto as duas arquiteturas coexistirem.
Implementando novas funcionalidades como microsserviços
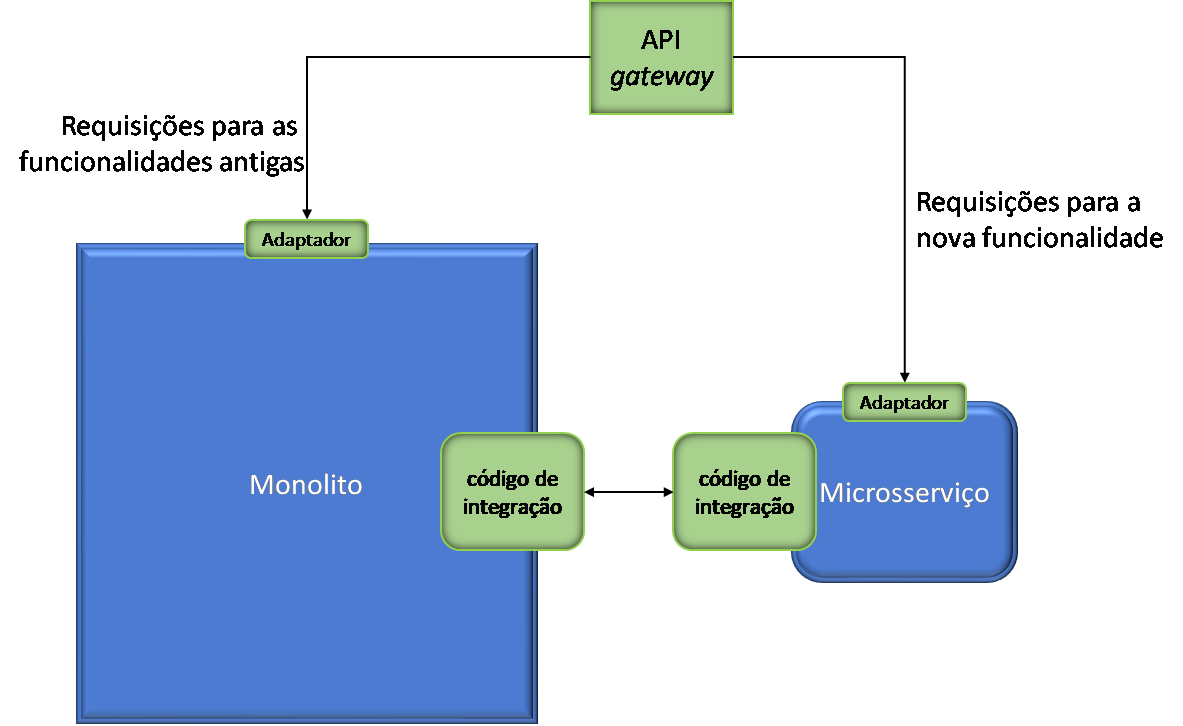
Vamos considerar que uma nova funcionalidade deva ser incorporada à aplicação e, que nesse caso, ela será implementada como um novo microsserviço (ou um conjunto deles), de acordo com a estratégia de migração adotada.
Nesse caso, o novo microsserviço também exporá sua funcionalidade através de uma API, e utilizaremos um API Gateway para rotear os requisitos para o novo componente ou para o monolito.
Ainda, provavelmente será necessário que o microsserviço interaja com o monolito, seja para acionar funcionalidades dele, seja para acessar ou gravar dados. Nesse caso, pode-se optar realizar a comunicação do microsserviço com a aplicação exclusivamente através das APIs, ou criar código de integração específico entre os dois elementos – o que pode ser necessário até por questões de desempenho.
Como resultado desse processo teremos:
- O monolito atual;
- O microsserviço que implementa a nova funcionalidade (ou um conjunto deles);
- Um API gateway que será utilizado para rotear as requisições para o monolito ou para o microsserviço;
- Um código de integração para que o microsserviço possa invocar as funcionalidades do monolito e acessar sua base de dados.
Migrar funcionalidades do negócio para microsserviços
Para a extração gradativa de funcionalidade da aplicação monolítica, a construção de cada microsserviço deverá levar em consideração a necessidade de integração com o restante da aplicação, e especialmente, o acesso aos dados de ambos os lados. É desejável que os microsserviços possuam suas próprias bases de dados, para garantir sua autonomia e proporcionar o desejável atributo de evolução e versionamento de maneira completamente independente da aplicação (e também de outros microsserviços).
Como uma etapa intermediária, pode ser necessário que o microsserviço compartilhe a base de dados da aplicação, mas essa deve ser uma situação temporária.
A completa separação entre o monolito e o microsserviço que implementará a funcionalidade extraída da aplicação inclui um desafio importante: a divisão do modelo de domínio da aplicação em dois novos domínios.
Separando o modelo do domínio
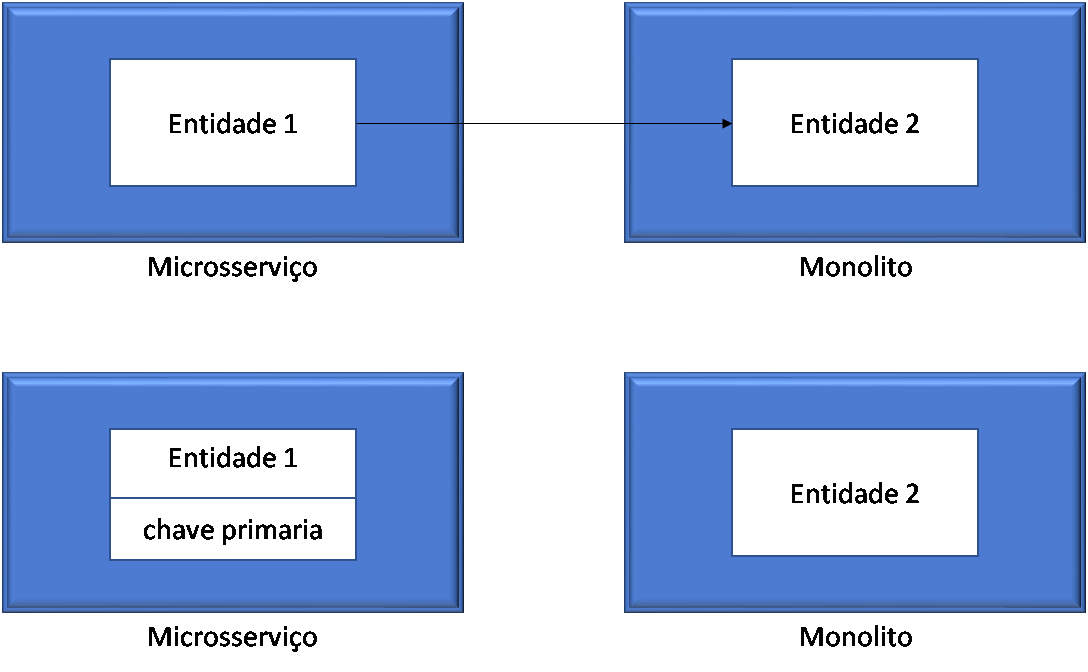
A extração de uma funcionalidade de um monolito implica em extrair o modelo de domínio dessa funcionalidade do modelo de domínio do monolito completo. Isso pode ser um desafio quando é necessário eliminar as referências a objetos em domínios diferentes para que não haja cruzamento entre as fronteiras dos microsserviços.
Uma possível forma de realizar essa separação de maneira ordenada, adaptando essas referências entre os diferentes domínios que agora passarão a residir em componentes de software diferentes (o monolito e o microsserviço), é a utilização do padrão aggregate do livro Domain-Driven Design.
Em linhas gerais, um aggregate é um conjunto de objetos de um determinado domínio que deve ser tratado como uma unidade. Um exemplo interessante, extraído dessa explicação de Martin Fowler, é um pedido e seus itens. Certamente, eles serão representados como objetos diferentes, mas serão tratados como um agregado. Todas as referências externas a esse conjunto de objetos deverão endereçar a raiz dessa árvore, isto é, o objeto que representa o pedido, encapsulando sua representação detalhada. O agregado será o elemento básico de transferência e para o mecanismo de persistência (um banco de dados, por exemplo). Ou seja, o domínio implementará a leitura e escrita do agregado como um todo, e as transações também deverão se restringir aos seus limites fronteiriços.
Assim, as referências a objetos pertencentes a outros domínios deverão ser substituídas por chaves primárias que identificam univocamente o objeto referenciado.
Solução intermediária
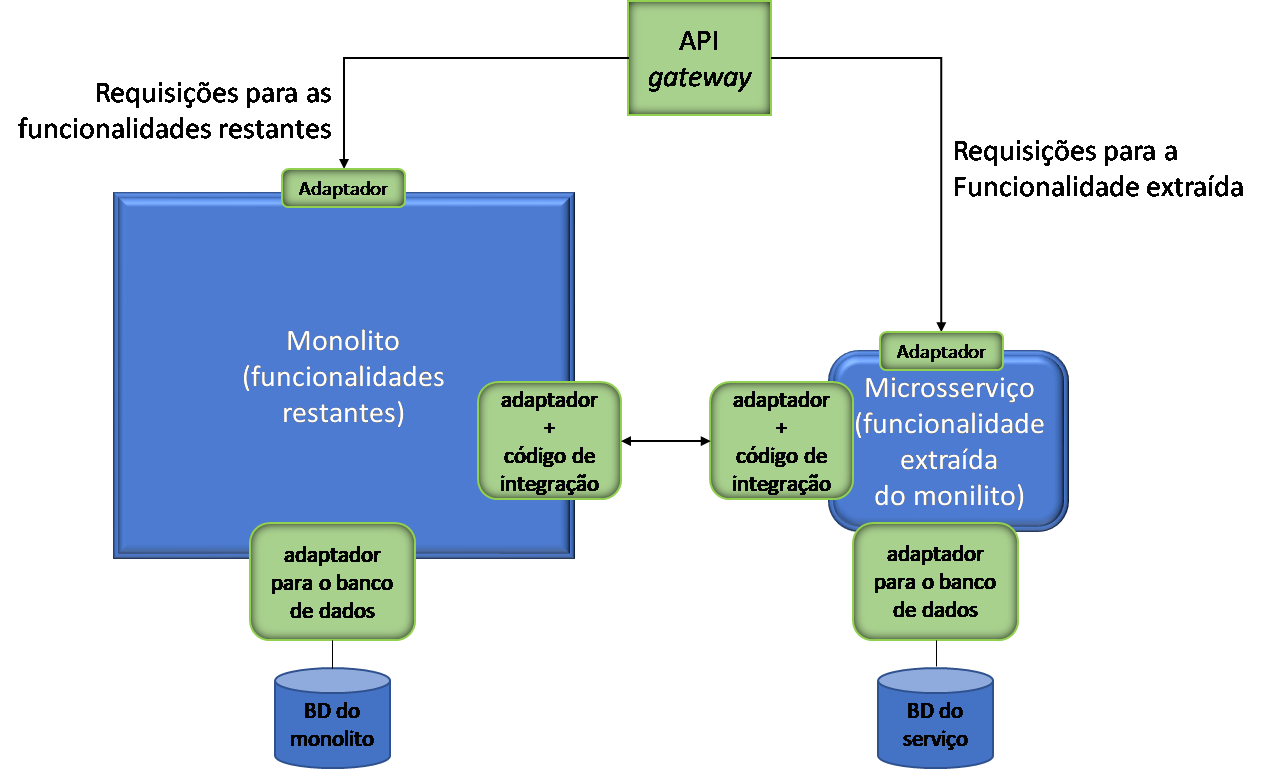
Essa mudança parece pequena a princípio, mas pode exigir uma reengenharia completa em parte do código. Uma solução intermediária, por um período de transição, seria manter a árvore de objetos completa no monolito (e em seu banco de dados) e replicar os dados necessários no microsserviço, usando gatilhos para sincronizar as bases de dados.
Para essa solução intermediária, os dados a serem incorporados pelo microsserviço que também permanecerem no monolito devem passar a ser apenas de leitura, e as atualizações passam a ser feitas apenas no microsserviço, e um mecanismo de sincronização deve ser implementado.
A solução definitiva deve trocar todas as referências ao aggregate no monolito para chaves primárias, e alterações nesses dados realizadas pela aplicação devem ser substituídas por chamadas ao microsserviço.
Quanto aos clientes da antiga aplicação, se a API do microsserviço referente à manipulação dos dados daquele domínio da aplicação for idêntica à do monolito, nenhuma alteração será necessária apenas será preciso alterar as tabelas de roteamento do API Gateway para direcionar as chamadas para a nova implementação. Caso seja necessário alterar a API, os clientes podem ser migrados ao longo do tempo, uma vez que o monolito continuará oferecendo as mesmas funcionalidades, embora precisando acionar o microsserviço para atender às chamadas referentes àquele domínio da aplicação.
Certamente, as abordagens já consolidadas sobre refatoração de banco de dados também podem ser usadas com essa estratégia de migração de funcionalidades para microsserviços. O importante é analisar qual abordagem é mais adequada, lembrando que, em algum momento futuro nesse processo de migração de monolito para microsserviço, esse código que faz referência aos dados replicados poderá se tornar ele próprio um novo microsserviço e as alterações necessárias já serão realizadas de forma definitiva.
Como resultado desse processo de migração de funcionalidade teremos:
- Um microsserviço que implementa a funcionalidade propriamente dita (a lógica do domínio);
- Código de integração entre o monolito e o novo microsserviço, incluindo as eventuais adaptadores para sincronização de dados entre os dois componentes;
- O esquema de banco de dados do microsserviço;
- O novo esquema de banco de dados do monolito, sem os dados que foram migrados.
Resumindo
Usar um processo incremental para realizar a refatoração do monolito em microsserviços garante a antecipação dos benefícios provenientes da nova abordagem. Entretanto, alguns problemas podem ser encontrados quando as funcionalidades do monolito são extraídas para os microsserviços. Nesses casos, algumas técnicas específicas já utilizadas em outras tecnologias também poderão ser utilizadas. A coexistência e a integração entre os microsserviços e o monolito é fundamental para que a aplicação continue funcionando adequadamente. Mas, acima de tudo, esse processo de migração deve respeitar as propriedades dos microsserviços e a integridade do monolito em cada etapa.


